ML Lecture 5 Support Vector Machine
基础概念与概览
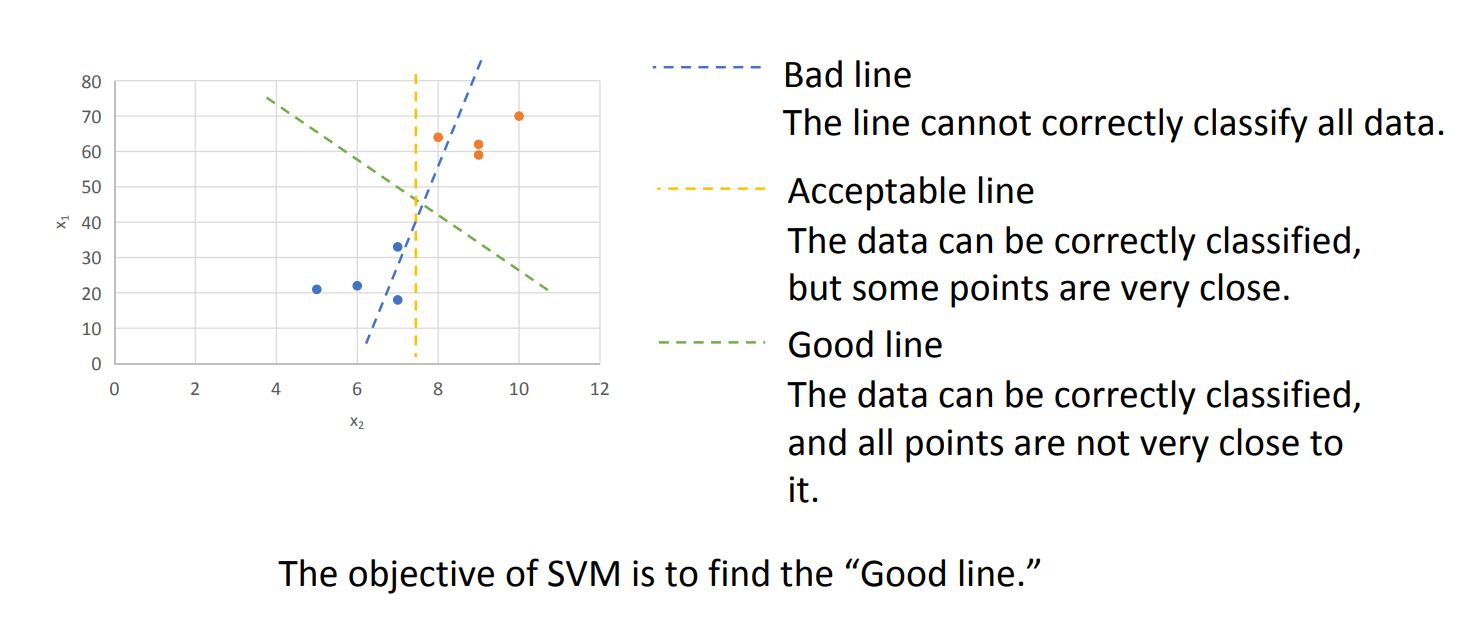
支持向量机(SVM)是一种强大的监督学习算法,主要用于分类(Classification)和回归(Regression)问题。
它的核心思想非常直观:试图在不同类别的数据点之间,找到一条“最宽的街道”(即最佳决策边界),将它们分开。
理解 SVM 需要掌握以下三个关键术语:
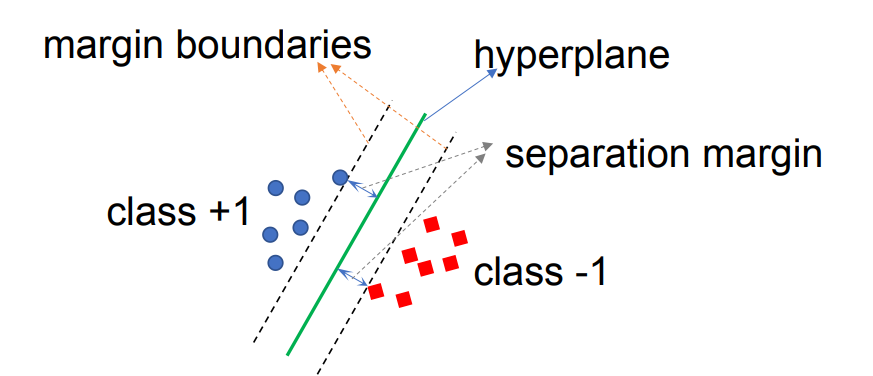
超平面 (Hyperplane): 这是区分数据的决策边界。
- 在二维平面上,它是一条线。
- 在三维空间中,它是一个面。
- 在更高维空间中,我们称之为超平面。
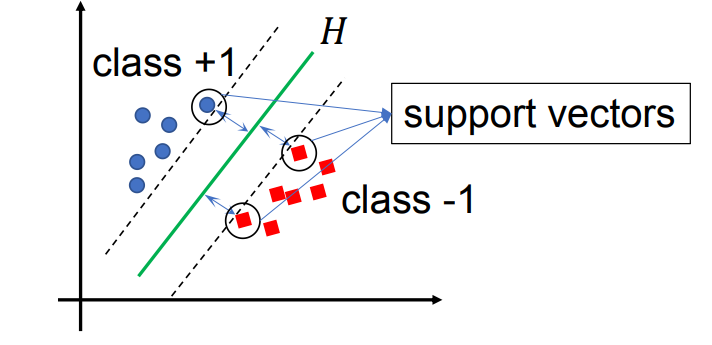
支持向量 (Support Vectors): 这些是距离超平面最近的数据点。
- 它们是“VIP”数据点,因为它们决定了超平面的位置和角度。
- 课件联系:在课件第26页提到的 RFE 方法中,线性 SVM 可被用作基础模型;RFE 通常利用线性 SVM 学到的权重向量来衡量特征重要性,而不是直接用支持向量本身作为特征权重。
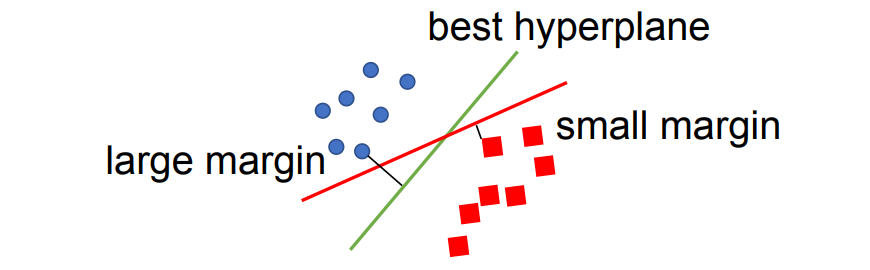
间隔 (Margin): 是指两条虚线(穿过支持向量且平行于超平面的线)之间的距离。SVM 的目标是最大化这个间隔。间隔越大,模型的泛化能力通常越好(越不容易过拟合)。
硬间隔 (Hard Margin): 要求所有数据点必须被完美分开,不能有错误。这通常只适用于数据非常干净且线性可分的情况,容易导致过拟合。
软间隔 (Soft Margin): 允许少量数据点跑到“错误”的一侧,以换取更大的间隔和更好的鲁棒性(通过参数
来控制这种容忍度)。
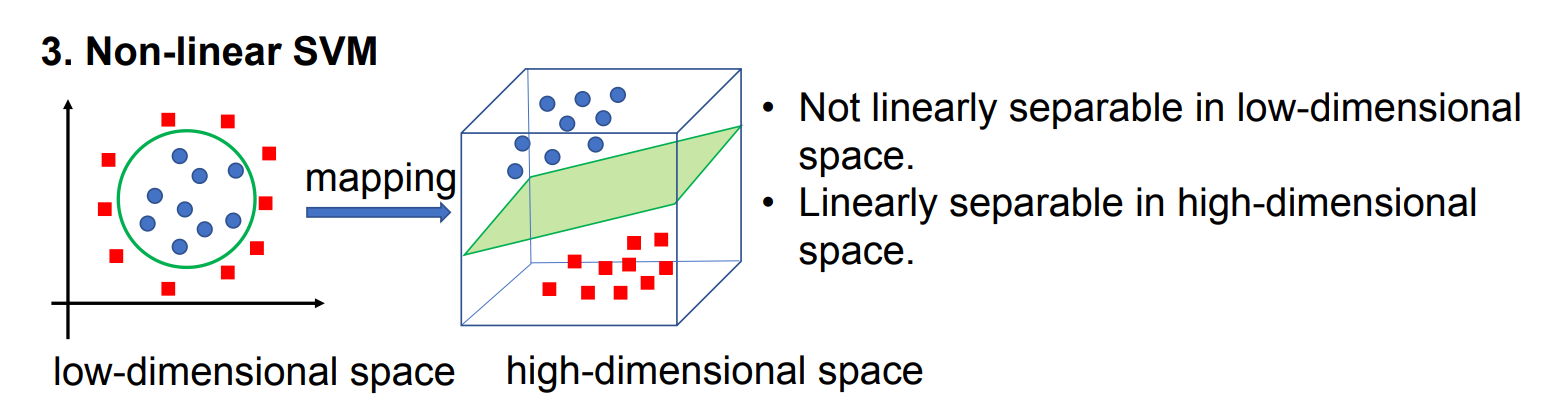
如果数据像“甜甜圈”一样,红球在中间,蓝球围在外面,你无法画一条直线把它们分开,怎么办?
SVM 引入了核函数 (Kernel Function)。它的作用是将低维空间的数据映射到高维空间。
例子: 在二维纸上画不出直线分开甜甜圈,但如果你把纸拎起来变成三维的圆锥,也许就能切一个平面把它们分开了。
常用的核函数:
- 线性核 (Linear Kernel)
- 多项式核 (Polynomial Kernel)
- RBF 核 (高斯核):最常用,适合处理复杂的非线性边界。
线性 SVM:硬间隔分类器
点与超平面的距离
- 定义:点到超平面的距离,是它到该超平面的垂线线段长度。
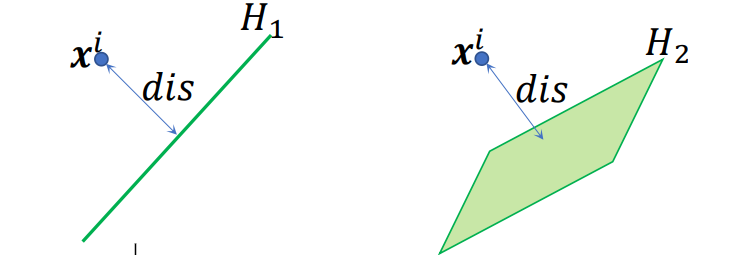
- 如果样本
落在超平面上,则它的距离为 - 如果
不在超平面上,则可以通过下面的距离公式计算。
设分类超平面为
则样本
其中,
间隔 Margin
数据集:
其中
是样本, 是标签(例如 对于给定超平面
定义为所有样本到超平面的最小距离: 间隔越大,分类器对自身预测越“有信心”。
SVM 的目标就是:在所有能够正确分类训练数据的超平面中,选出间隔最大的那一个。
线性可分下的 SVM
考虑来自两类、且线性可分的数据:
其中
定义一条直线(超平面):
约定:当
判为类别 A;当 判为类别 B。在线性可分的硬间隔设定中,训练样本不应落在两条间隔边界之间。
因此希望:寻找一条直线
使其通过类别 A 中的某个样本点,并且对所有样本都满足
在此基础上,再找一条与之平行的直线
使其通过类别 B 中的某个样本点,并同样满足上述约束。
两条平行直线之间的距离为通过合适的优化方法(如二次规划、梯度下降等)最大化
,从而求得最优的 和 。 将
作为最终的分类超平面,不同类别的样本将分布在该直线(超平面)的两侧。
将学习问题转化为优化问题(Learning as optimization in SVM)
- 对于给定的超平面
。 是关于参数 与 的函数。 - 我们希望在保证所有数据点都被正确分类的前提下,最大化间隔
。
该问题等价于下面的优化形式:
约束为:
- 这样,就把原来的“学习问题”转成了一个带约束的最优化问题。
- 这一优化问题可以通过二次规划等方法较为高效地求解。
线性 SVM:软间隔分类器
1. 现实场景中的问题
在真实场景中,数据集往往并不能完全线性可分,其中一个重要原因是存在异常点(outliers)。
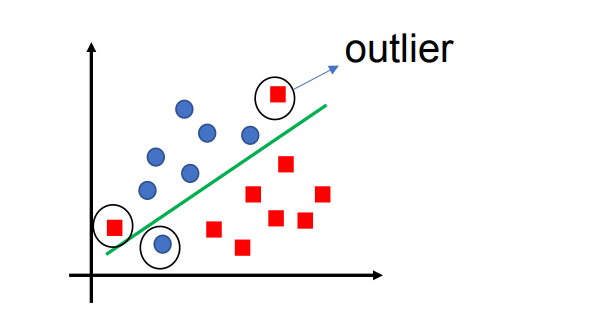
软间隔 SVM 的基本思想:
- 允许一定的误分类,但对误分类给予惩罚(penalty);
- 在最大化间隔与最小化间隔违例/误分类惩罚之间做折中(trade-off)。
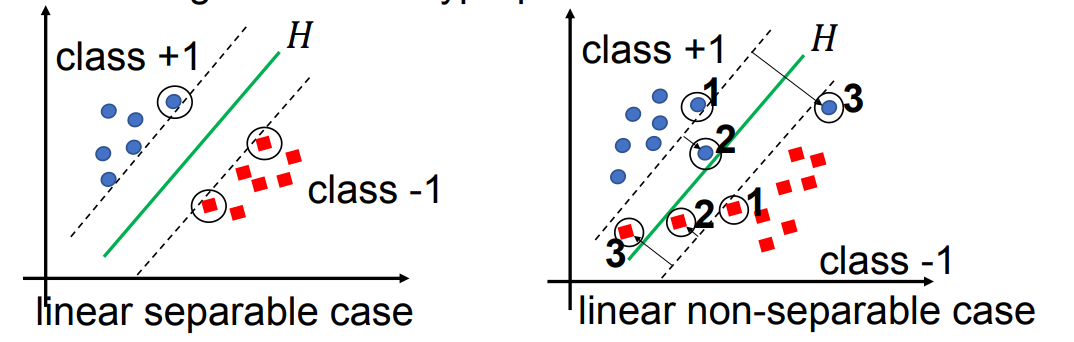
2. 不可分情形下的支持向量(Support vectors in non-separable case)
回顾:在线性可分情形中,支持向量只有一种类型:
- 位于间隔边界margin boundaries上的点。
在线性不可分情形中,支持向量大致可以分为三类:
- 仍然位于间隔边界上的点;
- 位于两条间隔边界之间,但仍在超平面正确一侧的点;
- 位于超平面“错误一侧”的点(即被分类错误的点)。
3. 软间隔的数学形式:加入松弛变量(slack variables)
引入松弛变量
硬间隔 SVM 的优化问题为:
软间隔 SVM 将其扩展为:
其中:
:第 个样本的松弛变量,表示它对间隔约束的违反程度; :惩罚系数 / 正则化超参数,控制“间隔大小”和“违例数量”之间的折中。
解释:
- 通过最小化
,我们希望总体的“间隔违例量”尽可能小; - 同时仍然最小化
来保持间隔尽可能大。
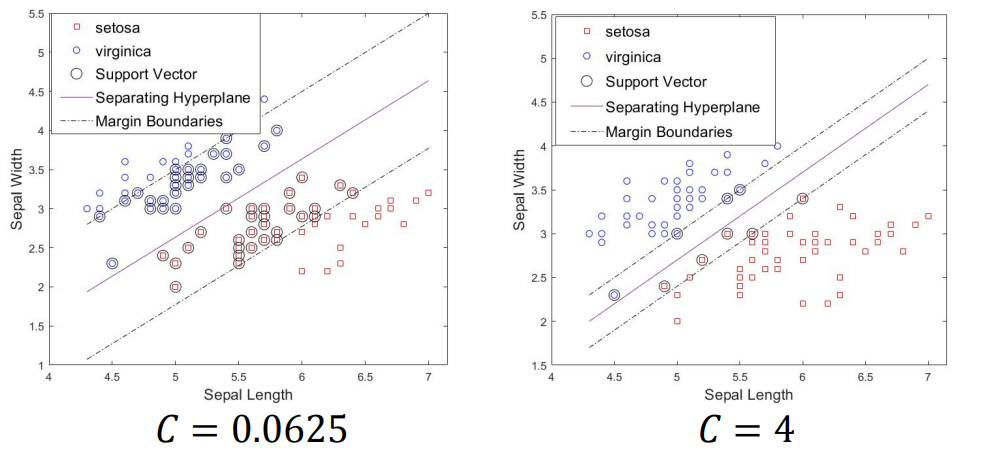
4. 超参数
在目标函数
中:
大: - 对违反间隔的惩罚很重;
- 更倾向于减少违例样本,哪怕间隔变窄;
- 间隔更“严格”,通常会减少间隔违例和误分类,但支持向量数量不一定单调减少。
小: - 允许更多的间隔违例和误分类;
- 更倾向于增大间隔;
- 支持向量数量更多,间隔更宽。
 极端情况下,当
极端情况下,当
非线性 SVM(Non-linear SVM)
线性 SVM 的局限性
- 线性分类器
- 无法解决明显的非线性分类问题。
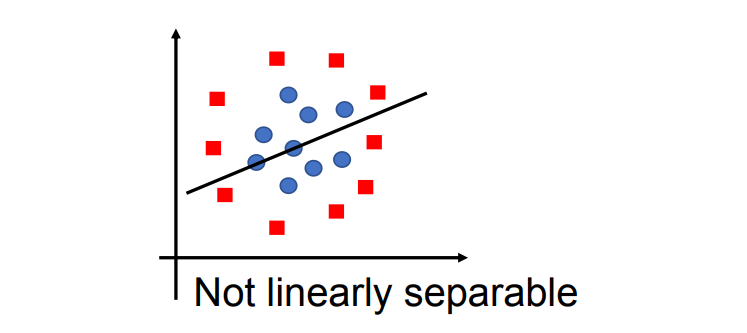 好消息:只要做一个小小的修改——使用 核技巧(kernel trick),SVM 就可以处理高度非线性的分类问题。
好消息:只要做一个小小的修改——使用 核技巧(kernel trick),SVM 就可以处理高度非线性的分类问题。
核函数(Kernel)
核函数(kernels):将数据变换成所需形式的函数。
基本思想:
- 先把数据映射到一个更高维的空间,使其在该空间中呈现出近似线性的结构;
- 然后在新的空间中学习一个线性分类器。
核函数完成的是从输入空间到特征空间的映射:
- 输入空间(input space):原始数据所在的空间;
- 特征空间(feature space):经过映射后的空间,希望数据在其中更容易被线性分类器分开,但不保证一定线性可分。
示例
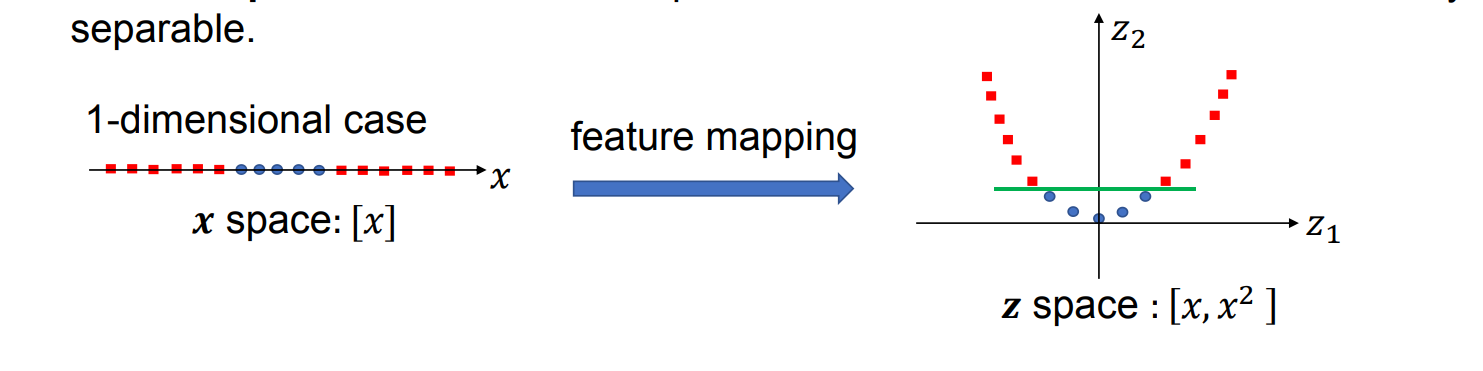
- 输入空间:
空间,写作 ; - 通过特征映射(feature mapping)后:
- 特征空间:
空间,可写成 。
同样的思想可以推广到二维:
输入空间:
空间, ; 通过特征映射后,得到特征空间:
在三维的
常用核函数(Widely used kernels)
一些常见、广泛使用的核函数:
线性核(Linear kernel)
二次核(Quadratic kernel)
多项式核(Polynomial kernel)
径向基核 / RBF 核(Radial Basis Function kernel)
高斯核(Gaussian kernel,RBF 核的常见形式)
如何选择合适的核函数(Choose the appropriate kernel)
核函数的选择应基于问题的性质和数据的特性;
对文本分类等高维稀疏特征问题,常优先选择线性核,在大数据集上表现稳定、计算效率高;
当缺乏额外的先验信息时,高斯核 / RBF 核通常是效果较好的通用选择;
实际应用中,通常通过交叉验证(cross-validation)来选择最优核函数及其超参数。
通过交叉验证选择核函数(Choose kernels by cross-validation)
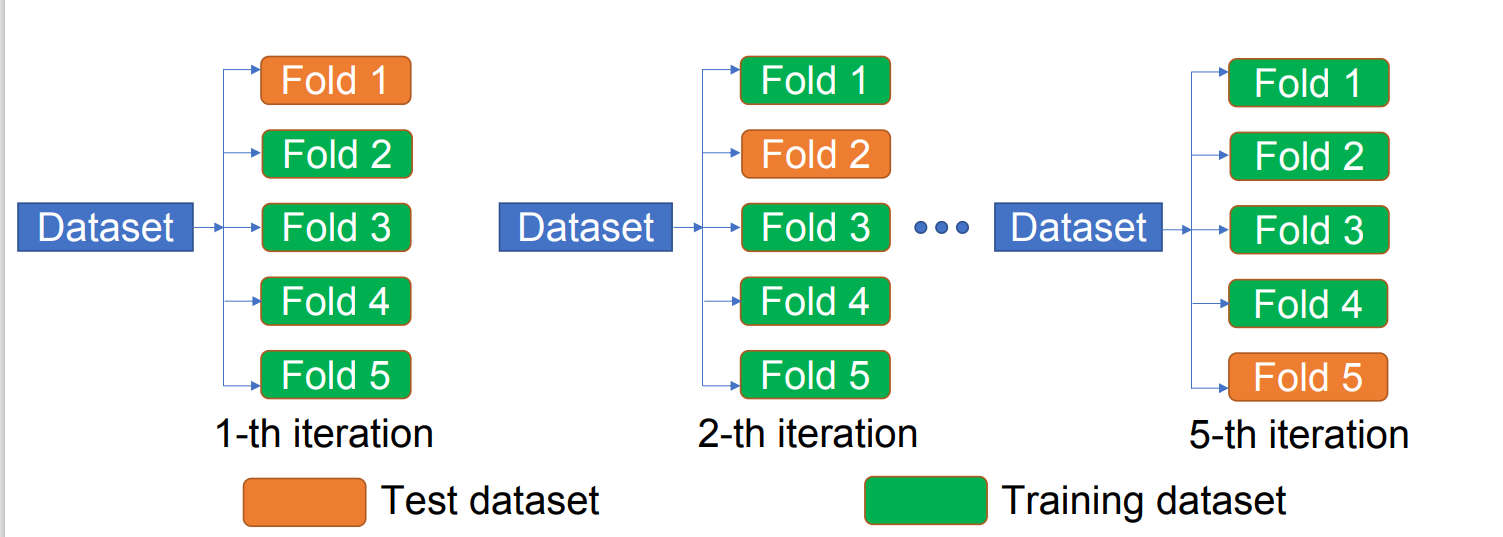
将数据集以不同方式划分为训练集和测试集,例如
折交叉验证( -fold): - 每一折中:选择其中一折为测试集,其余为训练集。
对每一个候选核函数,在每一次划分(每一折)上分别训练模型并进行测试,得到该折上的预测准确率。
假设有三个候选核函数:线性核、多项式核、RBF/Gaussian 核。
经过折交叉验证后,将得到: - 线性核:
; - 多项式核:
; - RBF/Gaussian 核:
。
- 线性核:
分别计算它们的平均预测准确率:
选择平均预测准确率最高的核函数作为最终的核。
多分类 SVM Multi-class SVM
- 标准的 SVM 是二分类(binary)分类器,本身并不直接支持多类别分类。
- 但很多实际任务都是多分类问题,例如:
- 手写数字识别(类别:0–9)
- 音乐推荐(rock、pop、metal、hip-hop 等)
多分类 SVM 的基本思想
核心思路:把一个多分类问题拆成多个二分类问题,再组合这些二分类器的结果。
两种常见拆分方式:
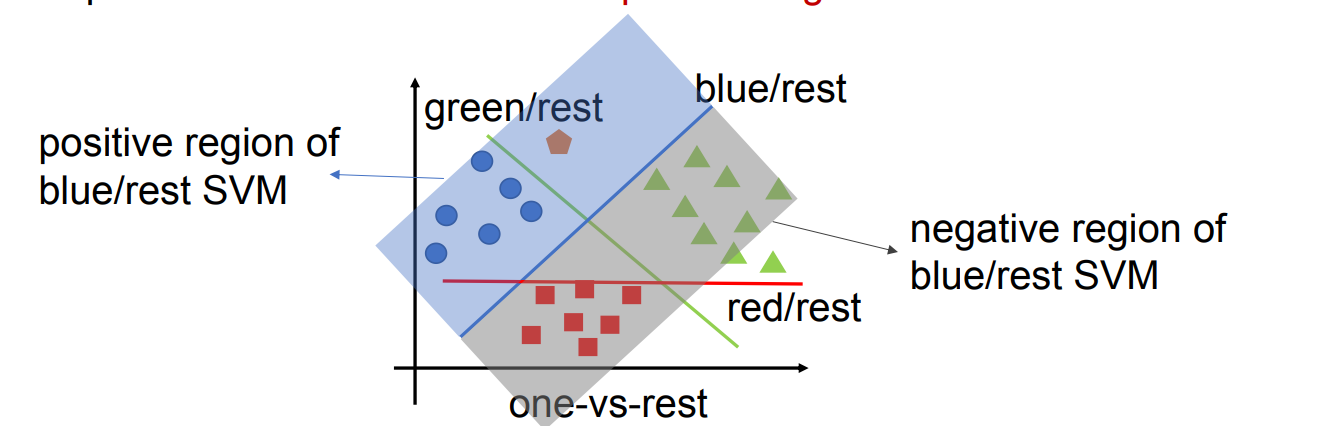
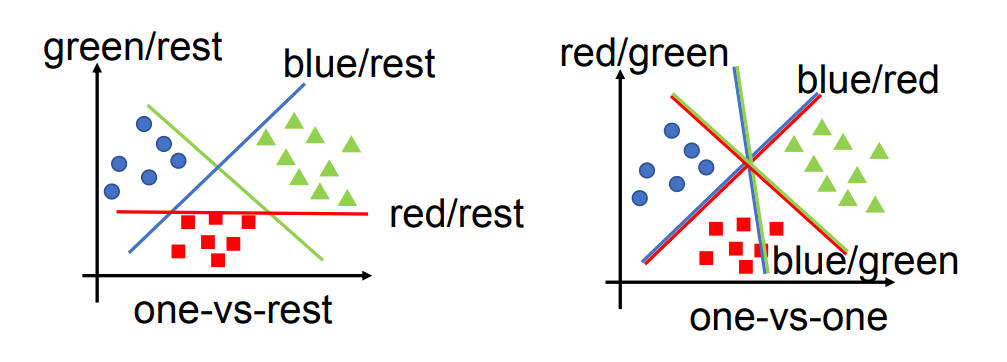
One-vs-Rest(OvR,一对多)
- 每次把“某一类”作为正类,其余所有类合并为“负类(Rest)”。
- 为每个类别都训练一个“该类 vs 其余所有类”的 SVM。
One-vs-One(OvO,一对一)
- 对每一对不同类别都训练一个 SVM。
- 每个 SVM 只区分两个类别。
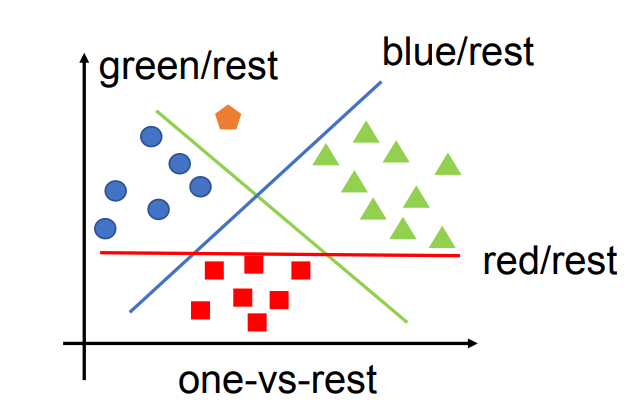
One-vs-Rest 方法
假设有一个
训练阶段(Learning)
- 对于第
个类别( - 正类:类别
- 负类:所有非
的类别(记为“Rest”)
- 正类:类别
共需要训练
- SVM 1:class
vs class - SVM 2:class
vs class - …
- SVM
:class vs class
预测阶段(Prediction)
对一个新样本
- 使用所有
个 SVM 进行预测,得到每个 SVM 的决策函数值(到超平面的距离)。 - 找出把
推到“正类区域”最深的那个 SVM: - 这个 SVM 对应的类别就是最终预测类别。
在 One-vs-Rest 中:
- Positive region(正类区域):该 SVM 的“目标类别(One)”所在的区域;
- Negative region(负类区域):包含其他所有类别(Rest)的区域。
One-vs-One 方法
同样假设有一个
训练阶段(Learning)
对每一对不同类别
( 需要训练的 SVM 个数为:
示例:
- SVM 1:class
vs class - SVM 2:class
vs class - …
- 最后一个:class
- SVM 1:class
预测阶段(Prediction)
对一个新样本
- 让所有
个 SVM 都对其进行预测: - 每个 SVM 在它负责的这两个类别中投票给一个类别(比如 “red/green SVM” 输出 red 或 green)。
- 统计每个类别得到的票数,进行多数表决(majority vote):
- 得票最多的类别就是最终预测结果。
例如,当三个 SVM 的预测为:
- blue/red SVM:预测 blue
- red/green SVM:预测 green
- blue/green SVM:预测 blue
则 blue 得到两票,green 一票,最终预测类别为 blue。